15. LPM6库¶
LPM6(LPM for IPv6)库组件实现了128位Key的最长前缀匹配表查找方法,该方法通常用于在IPv6转发应用程序中找到最佳匹配路由。
15.1. LPM6 API概述¶
LPM6库主要配置参数有:
- 支持的LPM规则最大数目:这定义了保存规则的表的大小,也就是最多可以添加的规则数目。
- tbl8的数量:tbl8是trie的一个节点,是LPM6算法的基础。
tbl8与您可以拥有的规则数量相关,但无法准确预测持有特定数量规则所需的空间,因为它强烈依赖于每个规则的深度和IP地址。一个tbl8消耗1 kb的内存。作为推荐,65536个tbl8应该足以存储数千个IPv6规则,但可能因情况而异。
LPM前缀由一对参数(128位Key,深度)表示,深度范围为1到128。LPM规则由LPM前缀和与前缀相关联的一些用户数据表示。该前缀作为LPM规则的唯一标识符。在当前实现中,用户数据为21位长,称为“下一跳”,对应于其主要用途,用于存储路由表条目中下一跳的ID。
为LPM组件导出的主要方法有:
- 添加LPM规则:LPM规则作为输入参数。如果表中没有存在相同前缀的规则,则将新规则添加到LPM表中。如果表中已经存在具有相同前缀的规则,则会更新规则的下一跳。当没有可用空间时返回错误。
- 删除LPM规则:LPM前缀作为输入参数。如果具有指定前缀的规则存在于LPM表中,则会被删除。
- 查找LPM规则:128位Key作为输入参数。该算法选择代表给定Key的最佳匹配的规则,并返回该规则的下一跳。在LPM表中存在多个具有相同128位Key值的规则的情况下,算法选择最高深度的规则作为最佳匹配规则,这意味着该规则在输入键和规则Key之间具有最高有效位数匹配。
15.1.1. 实现细节¶
这个实现是用IPv4的算法做的修改(参见IPv4 LPM实现细节)。在这种情况下,不是使用两级表,而是使用一级的tbl24和14级的tbl8。
该实现可以看作是一个Multi-bit trie,在每个级别上检查的步长或位数根据级别有所不同。具体来说,在根节点检查24位,剩下的104位以8位的组进行检查。这意味根据添加到表中的规则,该trie最多具有14个级。
该算法允许用户直接通过存储器访问操作来执行规则查找,存储器访问次数直接取决于规则长度,以及在数据结构中是否存在具有较大深度的其他规则和相同的Key。它可以在1到14次访存操作之间变化,IPv6中最常用的长度的平均值为5次访问操作。 主要数据结构使用以下元素构建:
- 一个有224个条目的表
- 具有28个条目的表,表的数目由API配置
第一个表称为tbl24,使用要查找的IP地址的前24位进行索引,其余表称为tbl8,使用IP地址的其余字节进行索引,大小为8位。这意味着尝试将输入数据包的IP地址与存储在tbl24或后续tbl8中的规则进行匹配的结果,我们可能需要在较深级别的树中继续查找过程。
类似于IPv4算法中的限制,为了存储所有可能的IPv6规则,我们需要一个具有2 ^ 128个条目的表。 由于资源限制,这显然是不可行的。
通过将查找过程分成不同的表/级别并限制tbl8的数量,我们可以大大减少内存消耗,同时保持非常好的查找速度(每级一个内存访问)。
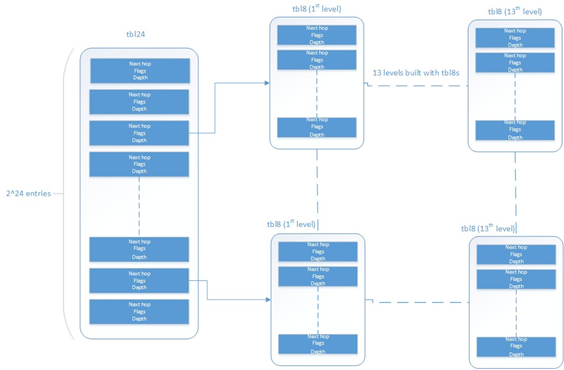
Fig. 15.4 Table split into different levels
表中的条目包含以下字段:
- 下一跳信息或者tbl8索引
- 规则深度
- 有效标志
- 有效组标志
- 外部条目标志
第一个字段可以包含指示查找过程应该继续的tbl8的索引,或者如果已经找到最长的前缀匹配,则可以包含下一跳本身。规则的深度或长度是存储在特定条目中的规则的位数。标志位用于确定条目/表是否有效以及搜索过程是否分别完成。 两种类型的表共享相同的结构。
另一个主要数据结构是一个包含规则(IP,下一跳和深度)的主要信息的表。这是一个更高级别的表,用于不同的目的:
- 在添加或删除之前,检查规则是否已经存在,而无需实际执行查找。
删除时,检查是否存在包含要删除的规则是很重要的,因为主数据结构必须相应更新。
15.1.2. 添加¶
添加规则时存在不同的可能性。如果规则的深度恰好是24位,那么:
- 添加规则时存在不同的可能性。如果规则的深度恰好是24位,那么:
- 如果条目无效(即表中原来不包含规则),则将其下一跳设置为其值,将有效标志设置为1(表示此条目正在使用中),并将外部条目标志设置为0(表示查找过程结束,因为这是匹配的最长的前缀)。
如果规则的深度大于24位,但倍数为8,则:
- 使用规则(IP地址)作为tbl24的索引。
- 如果条目无效(即它不包含规则),则查找一个空闲的tbl8,将该值的tbl8的索引设置为该值,将有效标志设置为1(表示此条目正在使用中),并将外部条目标志为1(意味着查找过程必须继续,因为规则尚未被完全探测)。
- 使用规则的下8位作为下一个tbl8的索引。
- 重复该过程,直到达到正确级别的tbl8(取决于深度),并将其填充到下一跳,将下一个条目标志设置为0。
如果规则的深度是其他值,则必须执行前缀扩展。这意味着规则被复制到所有条目(尽管它们不被使用)以实现致匹配。
举一个简单的例子,我们假设深度是20位。这意味着有可能导致匹配的IP地址的前24位的2 ^(24-20)= 16种不同的组合。因此,在这种情况下,我们将完全相同的条目复制到由这些组合索引的每个位置。
通过这样做,我们确保在查找过程中,如果存在与IP地址匹配的规则,则最多可以在14个内存访问中找到,具体取决于需要移动到下一个表的次数。前缀扩展是该算法的关键之一,因为它通过添加冗余显著提高速度。
前缀扩展可以在任何级别执行。因此,例如,深度是34位,它将在第三级(第二个基于tbl8的级别)执行。
15.1.3. 查询¶
查找过程要简单得多,速度更快。在这种情况下:
- 使用IP地址的前24位作为tbl24的索引。如果该条目未被使用,那么这意味着我们没有匹配此IP的规则。如果它有效并且外部条目标志设置为0,则返回下一跳。
- 如果它有效并且外部条目标志被设置为1,那么我们使用tbl8索引来找出要检查的tbl8,并且将该IP地址的下一个8位作为该表的索引。类似地,如果条目未被使用,那么我们没有与该IP地址匹配的规则。如果它是有效的,那么检查外部条目标志以检查新的tbl8。
- 重复该过程,直到找到无效条目(查找未命中)或外部条目标志设置为0的有效条目。在后一种情况下返回下一跳。
15.1.4. 规则数目限制¶
有不同的因素限制可以添加的规则数量。第一个是规则的最大数量,这是通过API传递的参数。一旦达到这个数字,就不可能再添加任何更多的规则到路由表,除非有一个或多个删除。
第二个限制是可用的tbl8数量。如果我们耗尽tbl8s,我们将无法再添加任何规则。很难提前确定其中有多少是特定的路由表所必需的。
在该算法中,单个规则可以消耗的tbl8的最大数量为13,这是级别数减1,因为前三个字节在tbl24中被解析。然而:
- 通常,在IPv6上,路由不超过48位,这意味着规则通常需要3个tbl8。
如在LPM for IPv4算法中所解释的,根据它们的第一个字节是多少,很可能会有几个规则共享一个或多个tbl8。如果它们共享相同的前24位,例如,第二级的tbl8将被共享。这可能会在更深的级别再次发生,所以有效的是,如果两个48位长的规则在最后一个字节中唯一的区别就可能使用相同的三个tbl8。
由于其对内存消耗的影响以及可以添加到LPM表中的数量或规则,tbl8的数量是在该版本的算法中通过API暴露给用户的参数。一个tbl8消耗1KB的内存。
15.2. 用例:IPv6转发¶
LPM算法用于实现实现IP转发的路由器所使用的无类别域间路由(CIDR)策略。