26. 报文框架¶
26.1. 设计目标¶
DPDK数据包框架的主要设计目标是:
- 提供标准方法来构建复杂的数据包处理流水线。 为常用的流水线功能模块提供可重复使用和可扩展的模板;
- 提供在同一流水线功能模块上在纯软件和硬件加速实现之间的切换能力;
- 提供灵活性和高性能之间的最佳权衡。 硬编码流水线通常提供最佳性能,但是不够灵活,而开发灵活的框架通常性能又较低;
- 提供一个逻辑上类似于Open Flow的框架。
26.2. 概述¶
报文处理应用程序通常被设计为多级流水线,每个阶段的逻辑围绕查找表进行。 对于每个传入的数据包,查找表定义了要应用于数据包的一组操作,以及数据包处理的下一个阶段。
DPDK数据包框架通过定义流水线开发的标准方法,以及为常用的流水线模块提供可重用的模板库来最大限度地减少 构建数据包流水线所需要的开发工作量。
将一组输入端口和一组输出端口通过树形拓扑中的一组查找表来连接以构成流水线。 作为当前报文查找表的查找结果,其中一个表条目(查找命中)或默认条目(查找缺失)提供了要对当前数据包应用的一组操作, 以及数据包的下一跳,可以是另一个表,输出端口或者是丢弃报文。
数据包处理流程的一个例子如下 Fig. 26.2:
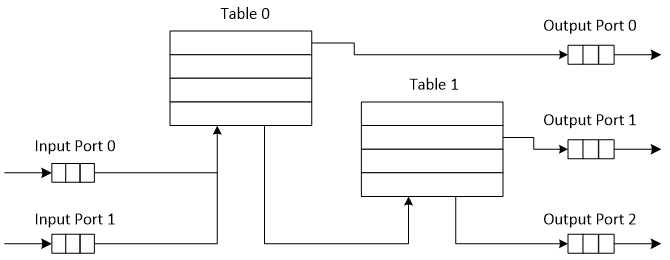
Fig. 26.2 输入端口0和1通过表0和表1与输出端口0,1和2连接的数据包流水线示例
26.3. 端口库设计¶
26.3.1. 端口类型¶
Table 26.2 是可以使用Packet Framework实现的端口的非穷尽列表。
| # | 端口类型 | 描述 |
|---|---|---|
| 1 | SW ring | 软件环形缓冲区用于应用程序之间的消息传递。使用DPDK的rte_ring。可能也是最常用的port类型 |
| 2 | HW ring | 用于与NIC、交换机或加速端口交互的缓冲区描述符队列。对于NIC端口,它使用rte_eth_rx_queue 或者rte_eth_tx_queue |
| 3 | IP reassembly | 输入数据包是完整的数据报或者片段。输出数据包则是完整的IP数据报。 |
| 4 | IP fragmentation | 输入数据包是Jumbo帧 (IP 数据报,长度大于 MTU) 或者非Jumbo帧。输出数据包是非Jumbo帧。 |
| 5 | Traffic manager | 连接到特定NIC输出端口的流量管理器,根据预定义的SLA执行拥塞管理和分级调度。 |
| 6 | KNI | 接收/发送数据包到/从Linux内核空间 |
| 7 | Source | 输入端口用作数据包生成器。 类似于Linux内核 /dev/zero 设备 |
| 8 | Sink | 输出端口,用于删除所有的输入数据包。类似于Linux内核的 /dev/null 字符设备。 |
26.4. 表库设计¶
26.4.1. 表类型¶
Table 26.4 是可以用Packet Framework实现的表类型的非穷举列表。
| # | 表类型 | 描述 |
|---|---|---|
| 1 | Hash table | 查找关键字是n-元组。 通常,查找key使用哈希算法以产生用于标识查找结果的索引值。 与每个数据包查找关键字相关的数据可以从数据包中读取(预先计算的), 或者在表查找时计算。 表查找、添加条目和删除条目操作,以及预先计算Key的任何流水线模块 都必须使用相同的哈希算法。 哈希表通常用于实现流分类表、ARP缓存、隧道协议路由表等。 |
| 2 | Longest Prefix Match (LPM) | 查找键值是IP地址。 表中的每个条目具有一个相关联的IP前缀。 表查找操作选择由查找键值匹配的IP前缀;在多个匹配的情况下,具有 最长前缀匹配的条目获胜。 通常用于实现IP路由表。 |
| 3 | Access Control List (ACLs) | 查找键值是7-元组,包括两个 VLAN/MPLS 标签,目的IP,源IP,L4协议, L4目的端口,L4源端口。 每个表条目具有相关联的ACL优先级。ACL包含VLAN/ MPLS标签的位掩码, IP目的地址的IP前缀,IP源地址的IP前缀,L4协议和位掩码,L4目的端 口和位掩码,L4源端口和位掩码。 表查找操作选择与查找键匹配的ACL; 在多个匹配的情况下,优先级最高 的条目胜出。 通常用于实现防火墙等规则数据库。 |
| 4 | Pattern matching search | 查找键值为报文负载。 表示一个模式数据库,每个模式都有一个相关联的优先级。 表查找操作选择与输入报文匹配的模式,在多个匹配的情况下,最高优 先级匹配胜出 |
| 5 | Array | 查询键是表条目索引本身。 |
26.4.2. 表操作接口¶
每个表都需要实现一个定义表的初始化和运行时操作的抽象接口。 表的抽象接口如下所述 Table 26.5.
| # | 表操作 | 描述 |
|---|---|---|
| 1 | Create | 创建查找表的低级数据结构。 可以内部分配内存。 |
| 2 | Free | 释放查找表使用的所有资源。 |
| 3 | Add entry | 向查找表添加新条目。 |
| 4 | Delete entry | 从查找表中删除特定条目。 |
| 5 | Lookup | 查找一组输入数据包,并返回一个指定每个数据包的查找操作结果的位掩码 一个位表示相应数据包的查找命中,而一个清除位被查找错过 对于每个查找命中数据包,查找操作也返回指向被命中的表条目的指针, 其中包含要应用于数据包的操作和任何关联的元数据。 对于每个查找缺失数据包,要应用于数据包的操作和任何关联的元数据由预先配置为 查找缺失的默认表条目指定 |
26.4.3. 哈希表设计¶
26.4.3.1. 哈希表概述¶
哈希表很重要,因为查找操作针对速度进行了优化:搜索操作仅限于表中的某个哈希桶,而不是在表中所有元素间进行线性查找。
关联数组
关联数组是一个可以被指定为一组(键,值)对的函数,每个键最多可以存在一个可能的输入键集合。 对于给定的一个关联数组,可能的操作如下:
- 添加 (key, value): 当没有value与当前 key*相关联时,(key, *value ) 关联将被创建。 当 key 已经关联了 value0,那么 (key, value0) 将被移除,并重新创建关联 (key, value) 。
- 删除 key: 假如当前没有value关联到 key,这个操作将不起作用。 当 key 已经关联了 value,那么 (key, value) 将被移除。
- 查找 key: 假如当前 key*没有关联的value,那么这个操作返回查找缺失。 当 *key 关联 value,那么这个操作将返回 value。 键值对 (key, value) 不做任何改变。
用于将输入key与关联数组中的key进行匹配的规则是 精确匹配,也就是说,key的大小及key值都必须精确匹配。
哈希函数
哈希函数确定性地将可变长度(密钥)的数据映射到固定大小的数据(散列值或密钥签名)。 通常地,key的大小要大于散列值的大小。 散列函数基本上将长key压缩成短哈希值。 几个key可以共享相同的哈希值,这就是哈希碰撞(哈希冲突)。
高质量散列函数可以做到均匀分布。 对于大量的key,当将哈希值的空间划分成固定数量的相等间隔(哈希桶)时,希望将哈希值均匀分布在这些间隔(均匀分布)上,而不是大多数哈希值 只分布在几个哈希桶中,其余的哈希桶在很大程度上没有使用(不均匀分布)。
哈希表
哈希表是使用散列函数进行操作的关联数组。 使用散列函数的原因是通过最小化必须与输入键进行比较的表键的数量来优化查找操作的性能。
哈希表不是将(key, value)对存储在单个链表中,而是保留多个链表(哈希桶)。 对于任意给定的key,存在单个哈希桶,并且该桶是基于key的哈希值唯一标识的。 一旦计算了哈希值,并且标识了哈希桶,key或者位于该桶中,或者根本不存在哈希表中,因此,根据key搜索可以从当前哈希表中唯一确认一个值。
哈希表查找的性能大大提高,前提是哈希表均匀分布在各个哈希桶之间,这个可以使用均匀分布的哈希函数来实现。 将key映射成哈希值的规则就是哈希函数,最简单的获取哈希桶的方式方式如下:
bucket_id = f_hash(key) % n_buckets;
通过选择桶的数量为2的幂,模运算符可以由按位AND逻辑来代替:
bucket_id = f_hash(key) & (n_buckets - 1);
为了减少哈希冲突,需要增加哈希表中哈希桶的数目。
在数据包处理上下文中,哈希表操作设计的操作顺序如下所示 Fig. 26.3:

Fig. 26.3 报文处理上下文中哈希表操作的步骤顺序
26.4.3.2. 哈希表用例¶
流分类
描述: 对于每个输入数据包,流分类至少执行一次。 此操作将每个输入的数据包映射到通常包含数百万条流的流数据库中的某一条已知流上。
哈希表名称: 流分类表
keys 数目: 百万个以上
Key 格式: 报文字段n元组,用于唯一标识一条流/连接。 例如: DiffServ 5元组(源IP地址、目的IP地址、L4协议、L4源端口、L4目的端口)。 对于IPv4协议,且L4协议如TCP、UDP或者SCTP,DiffServ 5元组的大小是13B,对于IP6协议则是37B。
Key 值: 用于描述对当前流的报文应用什么样的处理动作和动作元数据。 与每个业务流相关的数据大小可以从8B到1KB不等。
ARP
描述: 一旦IP数据包的路由找到,也就是说输出接口和下一个中继站的IP地址是已知的,那么就需要下一个中继站的MAC地址,以便将数据包发到下一站。 下一跳的MAC地址成为输出以太网帧的目标MAC地址。
哈希表名称: ARP表
keys 数目: 数千个
Key 格式: 键值对(输出接口,下一跳IP地址),通常IPv4是5B,IPv6是17B。
Key 值: 下一跳MAC地址6B。
26.4.3.3. 哈希表类型¶
Table 26.6 列出了所有不同散列表类型共享的散列表配置参数。
| # | 参数 | 描述 |
|---|---|---|
| 1 | Key size | 按照字节数来衡量,所有的Key具有相同的大小。 |
| 2 | Key value (key data) size | 按照字节数来衡量 |
| 3 | Number of buckets | 必须是2的幂次. |
| 4 | Maximum number of keys | 必须是2的幂次. |
| 5 | Hash function | 如: jhash, CRC hash, etc. |
| 6 | Hash function seed | 传递给哈希函数的参数。 |
| 7 | Key offset | 存储在分组缓冲器中的分组元数据内的查找键字节阵列的偏移。 |
26.4.3.3.1. 哈希桶溢出问题¶
在初始化时,为每个哈希表的桶分配4个keys的空间。 随着keys被添加到哈希表中,可能出现某个哈希桶中已经有4个keys的情况。 可以使用的方法有:
- LRU哈希表 哈希桶中现有的key之一将被删除以添加新的key到他的位置。 每个哈希桶中的key数目不会超过4个。选择要丢弃的key的规则是LRU。 哈希表查找操作维护同一个哈希桶中不同key命中的顺序,所以,每当命中key时,该key就成为最近使用的key(MRU),因此LRU的key通常在链表尾部。 当一个key被添加到哈希桶中时,它也成为新的MRU。 当需要选取和丢弃一个key时,第一个丢弃候选者,即当前的LRU Key总是被挑选出来丢弃。 LRU逻辑需要维护每个桶的特殊数据结构。
- 可扩展桶的哈希表. 哈希桶可以扩展空间,以存储4个以上的key。 这是通过在表初始化时分配额外的内存来实现的,这个内存用于创建一个空闲的key池(这个池的大小可配置,总是是4的倍数)。 在添加key操作中,可以分配一组(4个key)的空间,如果空间不足,则添加失败。 在删除key操作中,当要删除的key是一组4个key中唯一使用的key时,将密钥删除,并将这组空间释放回key池。 在查找key操作中,如果当前存储的哈希桶处于扩展状态,并且在第一组4个key中找不到匹配项,则搜索将在后续的key中继续进行,知道桶中所有的key都被检查。 可扩展桶的哈希表需要维护每个表和每个存储哈希桶的特定数据结构。
| # | Parameter | Details |
|---|---|---|
| 1 | Number of additional keys | 需要是2的幂次,至少是4 |
26.4.3.3.2. 哈希值计算¶
哈希值计算的可用方法包括:
- 预选计算的哈希值 Key查找操作被拆分到两个cpu core上。 第一个cpu core(通常是执行数据包接收的cpu core)从输入数据包中提取key,计算哈希值,并肩key和哈希值保存在接受数据包的缓冲区中作为数据包元数据。 第二个cpu core从数据包元数据中读取key和哈希值,并执行key查找操作。
- 查找过程中计算的哈希值 相同的cpu core从数据包元数据中读取key,用它来计算哈希值,并执行key查找操作。
| # | Parameter | Details |
|---|---|---|
| 1 | Signature offset | 数据包元数据内预先计算的哈希值的偏移 |
26.4.3.3.3. Key大小优化的哈希表¶
对于特定的key大小,key查找操作的数据结构和算法可以进行特殊的处理,以进一步提高性能,因此有如下选项:
- 支持可配置密钥大小的实现
- 实现支持单个密钥大小 通常key大小为8B或者16B。
26.4.3.4. 可配置Key大小的哈希表查找操作¶
哈希桶搜索的性能是影响key查找的最要因素之一。 数据结构和算法旨在充分利用Intel CPU架构资源如:缓冲区存储结构,缓冲区存储带宽,外部存储器带宽,并行工作的多个执行单元,无序指令执行,特殊CPU指令等等。
哈希桶搜索逻辑并行处理多个输入数据包。 它被构建为几个阶段(3或者4阶段)流水线,每个流水线阶段处理来自突发输入的两个报文。 在每个流水线迭代中,数据包被推送到下一个流水线阶段:对于4阶段的流水线,两个数据包(刚刚完成阶段3)退出流水线,两个数据包(刚刚完成阶段2)正在执行阶段3,两个数据包(刚刚完成阶段1)正在执行阶段2,两个数据包(刚刚完成阶段0)正在执行阶段1,两个数据包(从输入数据包中读取)正在执行阶段0。 流水线持续迭代,直到来自输入分组的所有报文全部出流水线。
哈希桶搜索逻辑在存储器访问边界处分成流水线的不同阶段。 每个流水线阶段(高概率)使用存储在当前CPU core的L1/L2 cache中的数据结构,并在算法要求的下一个存储器访问之前终止。 当前流水线阶段通过预取下一个阶段需要的数据结构来完成,当下一个流水线阶段执行时,可以直接从L1/L2 cache中读取数据,从而避免L2/L3 cache miss造成的性能损失。
通过预取下一个水线阶段需要的数据结构,并且切换到针对不同分组的另一个流水线阶段,L2/L3 cache miss会大大减少。 这是因为在存储器读取L2 /L3 cache miss的数据成本很高,通常由于指令之间的数据依赖性,CPU执行单元必须停止,直到从L3高速缓冲存储器或外部DRAM存储器完成读取操作。 通过使用预取指令,存储器读取访问的延迟是隐藏的,只要在相应的数据结构被实际使用之前足够早地执行。
通过将处理分成在不同分组上执行的几个阶段(来自输入突发的分组交错),创建足够的工作以允许预取指令成功完成(在预取的数据结构被实际访问之前)以及数据指令之间的依赖关系被松动了。例如,对于4级流水线,对包0和1执行阶段0,然后在使用相同包0和1之前(即,在包0和1上执行阶1之前),使用不同的包:包2和3(执行阶段1),分组4和5(执行阶段2)以及分组6和7(执行阶段3)。 通过在将数据结构带入L1或L2高速缓冲存储器的同时执行有用的工作,隐藏了读取存储器访问的等待时间。 通过增加对同一数据结构的两次连续访问之间的差距,减轻了指令之间的数据依赖性;这允许最大限度地利用超标量和无序执行CPU架构,因为处于活动状态的CPU核心执行单元的数量(而不是由于指令之间的数据依赖性约束而空闲或停滞)被最大化。
哈希桶搜索逻辑也是在不是用任何分支指令的情况下实现的。 这避免了在每个分支错误预测实例上刷新CPU core执行管道的相关消耗。
26.4.3.4.1. 可配置Key大小的哈希表¶
Fig. 26.4, Table 26.9 and Table 26.10 详细介绍用于实现可配置Key大小的哈希表的主要数据结构。
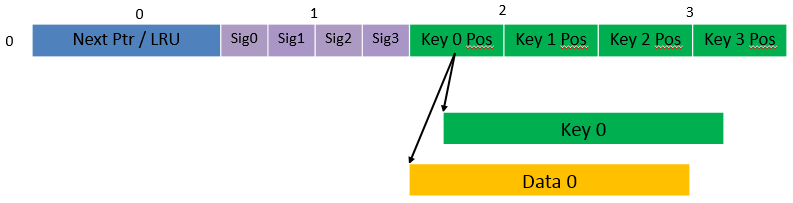
Fig. 26.4 可配置Key大小的散列表的数据结构
| # | 数组名 | 条目数 | 条目大小 (字节) | 描述 |
|---|---|---|---|---|
| 1 | Bucket array | n_buckets (可配置) | 32 | 哈希表的桶数目 |
| 2 | Bucket extensions array | n_buckets_ext (可配置) | 32 | 只有可扩展哈希桶才会有 |
| 3 | Key array | n_keys | key_size (可配置) | Keys |
| 4 | Data array | n_keys | entry_size (可配置) | Key values |
| # | Field name | Field size (bytes) | Description |
|---|---|---|---|
| 1 | Next Ptr/LRU | 8 | 对于LRU表,这些字段表示当前哈希桶的LRU列表 每个存储为2B的4个条目数组。 条目0存储MRU Key的索引(0..3),而条目3存储LRU Key的索引。 对于可扩展桶表,该字段表示下一个指针(即指向链接到当前桶的 下一组4个Key的指针)。如果存储桶当前已扩展,则下一个指针不为NULL 如果下一个指针不为NULL,则将该字段的位0设置为1,否则置位0。 |
| 2 | Sig[0 .. 3] | 4 x 2 | 如果 key X (X = 0 .. 3) 有效,则 sig X 的 bits 15 .. 1 存储 哈希值的最高 15 bits,而sig X bit 0 设置为1。 如果 key X 无效, sig X 被设置为0。 |
| 3 | Key Pos [0 .. 3] | 4 x 4 | 如果 key X (X = 0 .. 3)有效,那么 Key Pos X 代表 存储Key X的数组的索引,以及存储与Key X相关联的值的数据数组索引 如果 key X 无效,Key Pos X 的值未定义。 |
Fig. 26.5 and Table 26.11 详细说明桶搜索流水线阶段(LRU或可扩展桶,预先计算哈希值或”do-sig”)。 对于每个流水线阶段,所描述的操作被应用于由该阶段处理的两个报文中的任何一个。

Fig. 26.5 用于Key查找操作的流水线(可配置Key大小的哈希表)
| # | Stage name | 描述 |
|---|---|---|
| 0 | 预取报文元数据 | 从输入数据包的突发中选择接下来的两个数据包。 预取包含Key和哈希值的数据包元数据。 |
| 1 | Prefetch table bucket | 从报文元数据中读取哈希值(对于可扩展表),从报文元数据中读取Key(LRU表) 使用哈希值识别桶ID。 设置哈希值的bit 0 为1 (用于匹配表中哈希值有效的Key) 预取桶。 |
| 2 | Prefetch table key | 从桶中读取哈希值。 将哈希值与报文中读取的哈希值进行对比,可能产生如下几种结果: match = TRUE(如果至少有一个哈希值匹配), FALSE(无哈希值匹配) match_many = TRUE(不止一个哈希值匹配,最多可以是4个),否则为FALSE。 match_pos = 哈希值匹配的第一个Key索引(当match为TRUE是才有效) 对于桶扩展的哈希表,如果next pointer有效设置 *match_many*为TRUE 预取由 match_pos 标识的Key。 |
| 3 | Prefetch table data | 读取由 match_pos 标识的Key。 将该Key与输入的Key进行对比,产生如下结果: match_key = TRUE(如果两个key匹配),否则为FALSE。 当且仅当 match 和 match_key 都为TRUE时报告查找命中,否则未命中。 对于LRU表。使用无分支逻辑来更新桶的LRU表(当查找命中时,当前Key更改为MRU) 预取Key值(与当前Key关联的数据域)。 |
额外注意:
- 桶搜索的流水线版本只有在输入突发中至少有7个包时才被执行。 如果输入突发中少于7个分组,则执行分组搜索算法的非优化实现。
- 一旦针对输入突发中的所有分组已经执行了桶搜索算法的流水线版本,则对不产生查找命中的任何分组,如果 match_many 已经设置了,那么将同时执行桶优化算法的非优化实现。 作为执行非优化版的结果,这些分组中的一些可能产生查找命中或者未命中。 这并不会影响Key查找操作的性能,因为在同一组4个Key中匹配多个哈希值的概率或者处于扩展状态的桶的概率相对较小。
哈希值比较逻辑
哈希值比较逻辑描述如下 Table 26.12.
| # | mask | match (1 bit) | match_many (1 bit) | match_pos (2 bits) |
| 0 | 0000 | 0 | 0 | 00 |
| 1 | 0001 | 1 | 0 | 00 |
| 2 | 0010 | 1 | 0 | 01 |
| 3 | 0011 | 1 | 1 | 00 |
| 4 | 0100 | 1 | 0 | 10 |
| 5 | 0101 | 1 | 1 | 00 |
| 6 | 0110 | 1 | 1 | 01 |
| 7 | 0111 | 1 | 1 | 00 |
| 8 | 1000 | 1 | 0 | 11 |
| 9 | 1001 | 1 | 1 | 00 |
| 10 | 1010 | 1 | 1 | 01 |
| 11 | 1011 | 1 | 1 | 00 |
| 12 | 1100 | 1 | 1 | 10 |
| 13 | 1101 | 1 | 1 | 00 |
| 14 | 1110 | 1 | 1 | 01 |
| 15 | 1111 | 1 | 1 | 00 |
输入的 mask 哈希 bit X (X = 0 .. 3) 设置为 1,如果输入的哈希值等于桶的哈希值X,否则则设置为0。 输出的 match, match_many 及 match_pos 是 1 bit, 1 bit 和 2 bits大小,其意义如上表描述。
如 Table 26.13 所描述的, match 和 match_many 的查找表可以折叠成一个32bit的值,match_pos 可以折叠成一个64bit的值。 给定输入的 mask ,match 的值, match_many 和 match_pos 的值可以通过索引他们各自的比特数来获得,分别用无分支逻辑取1,1和2 bits。
| Bit array | Hexadecimal value | |
| match | 1111_1111_1111_1110 | 0xFFFELLU |
| match_many | 1111_1110_1110_1000 | 0xFEE8LLU |
| match_pos | 0001_0010_0001_0011__0001_0010_0001_0000 | 0x12131210LLU |
计算match, match_many 和 match_pos 的伪代码:
match = (0xFFFELLU >> mask) & 1;
match_many = (0xFEE8LLU >> mask) & 1;
match_pos = (0x12131210LLU >> (mask << 1)) & 3;
26.4.3.4.2. 单一Key大小的哈希表¶
Fig. 26.6, Fig. 26.7, Table 26.14 and Table 26.15 详细描述了用于实现8B和16B Key的哈希表的主要的数据结构(包括LRU或扩展桶表,预先计算哈希值或”do-sig”)。

Fig. 26.6 8B Key哈希表数据结构

Fig. 26.7 16B Key哈希表数据结构
| # | Array name | Number of entries | Entry size (bytes) | Description |
|---|---|---|---|---|
| 1 | Bucket array | n_buckets (configurable) | 8-byte key size: 64 + 4 x entry_size 16-byte key size: 128 + 4 x entry_size |
该哈希表的桶 |
| 2 | Bucket extensions array | n_buckets_ext (configurable) | 8-byte key size: 64 + 4 x entry_size 16-byte key size: 128 + 4 x entry_size |
仅用于扩展桶的哈希表 |
| # | Field name | Field size (bytes) | 描述 |
|---|---|---|---|
| 1 | Valid | 8 | 如果Key X有效,那么Bit X (X = 0 .. 3) 设置为1,否则为0。 Bit 4 仅用于扩展桶的哈希表,用来帮助实现无分支逻辑。 在这种情况下,如果next pointer有效,bit 4 设置为1,否则为0。 |
| 2 | Next Ptr/LRU | 8 | 对于LRU表,这个字段代表了当前桶中的LRU表。以2B代表4个条目存储为数组。 条目 0 存储 MRU key (0 .. 3),条目3存储LRU Key。 对于可扩展桶表,该字段表示下一个指针(即指向链接到当前桶的下一组4个键的指针) 如果存储桶当前被扩展,则下一个指针不为NULL;否则为NULL。 |
| 3 | Key [0 .. 3] | 4 x key_size | Full keys. |
| 4 | Data [0 .. 3] | 4 x entry_size | Full key values (key data) associated with keys 0 .. 3. |
详细介绍用于实现8B和16B大小的Key的哈希表(包括LRU或可扩展桶表,预先计算哈希值或者”do-sig”)。 对于每个流水线阶段,所描述的操作被应用于由该阶段处理的两个分组中的每一个。

Fig. 26.8 用于Key查找操作的桶搜索水线(单一Key大小的哈希表)
| # | Stage name | Description |
|---|---|---|
| 0 | Prefetch packet meta-data |
|
| 1 | Prefetch table bucket |
|
| 2 | Prefetch table data |
|
额外注意:
- 桶搜索算法的流水线版本只有在输入突发中至少有5个包时才会执行。 如果在输入分组突发中少于5个分组,则执行分组搜索算法的非优化实现。
- 对于可扩展的分组哈希表,一旦已经对输入分组的突发中的所有分组执行了桶搜索算法的流水线版本,对于没有产生的任何分组但有扩展状态的桶,也执行桶搜索算法的非优化实现 查找命中。 作为执行非优化版本的结果,这些分组中的一些可能产生查找命中或查找未命中。 这不影响密钥查找操作的性能,因为处于扩展状态的桶的概率相对较小。
26.5. 流水线库设计¶
一个流水线由如下几个元素定义:
- 一组输入端口;
- 一组输出端口;
- 一组查找表;
- 一组动作集。
输入端口通过互连表格的树状拓扑连接到输出端口。 表项包含定义在输入数据包上执行的动作和管道内的数据包流。
26.5.1. 端口和表的连接¶
为了避免对流水线创建顺序的依赖,流水线元素的连通性在所有水线输入端口、输出端口和表创建完之后被定义。
一般的连接规则如下:
- 每个输入端口连接到一个表,没有输入端口是悬空的;
- 与其他表或输出端口的表连接由每个表条目和默认表条目的下一跳动作来调节。
表连接性是流畅的,因为表项和默认表项可以在运行时更新。
- 一个表可以有多个条目(包括默认条目)连接到同一个输出端口。 一个表可以有不同的条目连接到不同的输出端口。 不同的表可以有连接到同一个输出端口的条目(包括默认条目)。
- 一个表可以有多个条目(包括默认条目)连接到另一个表,在这种情况下,所有这些条目都必须指向同一个表。 这个约束是由API强制的,并且防止了树状拓扑的建立(只允许表连接),目的是简化流水线运行时执行引擎的实现。
26.5.2. 端口动作¶
26.5.2.1. 端口动作处理¶
可以为每个输出/输出端口分配一个操作处理程序,以定义在端口接收到的每个输入数据包上执行的操作。 为特定的输入输出端口定义动作处理程序是可选的。(即可以禁用动作处理程序)
对于输入端口,操作处理程序在RX功能之后执行。对于输出端口,动作处理程序在TX功能之前执行。
操作处理程序可以快速丢弃数据包。
26.5.3. 表动作¶
26.5.3.1. 表动作处理¶
每个输入数据包上执行的操作处理程序可以分配给每个表。 为特定表定义动作处理程序是可选的(即可以禁用动作处理程序)。
在执行表查找操作之后执行动作处理程序,并且识别与每个输入分组相关联的表项。 操作处理程序只能处理用户定义的操作,而保留的操作(如下一跳操作)则由分组框架处理。 操作处理程序可以决定丢弃输入数据包。
26.5.3.2. 预留动作¶
保留的动作有数据包框架直接处理,用户无法通过表动作处理程序配置更改其含义。 保留动作的一个特殊类别由下一跳动作来表示,它通过流水线来调节输入端口、表格和输出端口之间的数据流。 Table 26.17 列出了下一跳动作。
| # | Next hop action | 描述 |
|---|---|---|
| 1 | Drop | 丢弃当前报文。 |
| 2 | Send to output port | 发送当前报文到指定的输出端口。输出端口ID是存储在表元素中的元素据。 |
| 3 | Send to table | 发送当前报文到指定的表,表D是存储在表元素中的元数据。 |
26.5.3.3. 用户动作¶
对于每个表,用户动作的含义都是通过表操作处理程序的配置来定义的。 不同的表可以配置不同的操作处理程序,因此用户动作及其相关元数据的含义对于每个表是私有的。 在同一个表中,所有表项(包括表默认项)共享用户动作及其相关元数据的相同定义,每个表项具有其自己的一组启用的用户动作以及它自己的操作副本元数据。
Table 26.18 包含用户动作的部分列表。
| # | User action | 描述 |
|---|---|---|
| 1 | Metering | 使用srTCM和trTCM算法的每流量计量。 |
| 2 | Statistics | 更新每个流维护的统计信息计数器。 |
| 3 | App ID | 每个流状态机在流初始化时通过可变长度的分组序列进行馈送, 以识别流量类型和应用。 |
| 4 | Push/pop labels | 对当前报文执行VLAN/MPLS标签的入栈和出栈 |
| 5 | Network Address Translation (NAT) | 内部和外部IP地址(源和目的)的转化,L4协议源/目的端口转换 |
| 6 | TTL update | 递减TP TTL值,及更新IPv4报文的校验和。 |
26.6. 多核处理¶
一个复杂的程序通常分成多核处理,多核之间通过SW队列进行通信。 由于以下硬件约束,在同一CPU内核上可以安装的表查找操作的数量通常有性能限制:了用的CPU周期,高速缓冲区的大小、高数缓存带宽、存储器传输带宽等。
由于应用程序跨越多个CPU核心,数据包框架便于创建多个流水线,将每个这样的流水线分配给不同的核心,并将所有的CPU核心级别的流水线互联为单个应用级复杂流水线。 例如,如果CPU核心A被分配运行流水线P1和CPU核心B流水线P2,则P1和P2的相互连接可以通过使相同的一组SW队列作为P1的输出端口和P2的输入端口来实现。
这种方法可以使用流水线,运行到完成(集群)或混合(混合)模型来开发应用程序。
允许同一个内核运行多个管道,但不允许多个内核运行相同的管道。
26.6.1. 共享的数据结构¶
执行表查询的线程实际上是写线程,不仅仅是读操作。 即便指定的表查找算法是多线程安全的读者(如搜索算法数据结构的只读访问足以进行查找操作), 一旦识别出当前报文的表项,通常期望线程更新存储在表项中的元数据(如增加命中该表项的数据包的计数器等),这写操作将修改表项。 在此线程访问表项期间(写入或读取;持续时间与应用程序相关),由于数据一致性原因,不允许其他线程(执行查表或者添加删除表项操作)来修改此表项。
在多个线程之间共享一个表的机制:
- 多个写线程 线程需要使用类似信号量(每个表项不同的信号量)或原子操作的同步原语。 信号量的耗时通常很高。 原子指令的耗时通常高于普通指令。
- 多个写线程,其中单个线程执行表查找操作,其他线程执行表添加、删除操作 执行表添加、删除操作的线程向读取器发送表更新请求(通常是通过消息队列传递),这些请求执行实际的表更新,然后将相应发送回请求发起者。
- 单个写线程执行表项添加、删除操作,多个度线程执行表查找操作,该查表操作只读表项,没有修改表项信息 读线程使用主表的副本,而写线程更新镜像副本。 一旦写更新操作完成,写线程发信号给读线程,并等待所有的读线程切换到镜像副本上。
26.7. 加速器¶
在初始化阶段通常通过检查作为系统一部分的HW设备(如通过PCI枚举操作)来检测加速器的存在。
具有加速功能的典型设备:
- 内联加速器:网卡、交换机、FPGA等;
- 外置加速器:芯片组、FPGA等
通常,为了支持特定功能模块,必须为每个加速器提供Packet Framework表、端口、动作的特定实现,所有实现共享相同的API:纯SW实现(无加速)、使用加速器A、使用加速器B等等。 这些实现之间的选择可以在构建或者在运行时完成,而不需要该变应用程序。