16. 报文分发库¶
DPDK报文分发器是一种库,用于在一次 操作中获取单个数据包,以支持流量的动态负载均衡。当使用这个库时,需要考虑两种角色的逻辑核:首先是负责负载均衡及分发数据包的分发逻辑核,另一个是一组工作逻辑核,负责接收来自分发逻辑核的数据包并对其进行操作。
操作模式如下图所示:
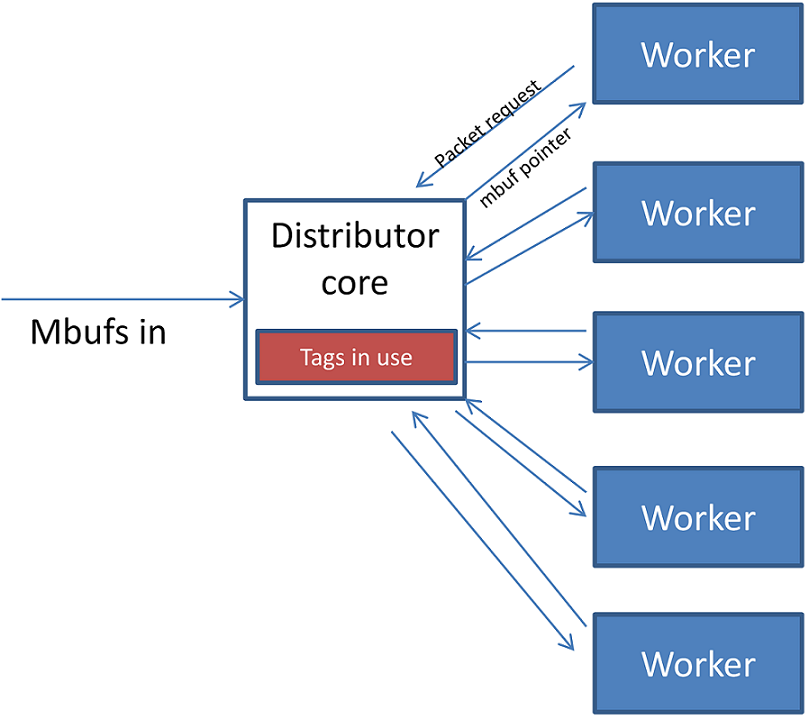
Fig. 16.1 Packet Distributor mode of operation
在报文分发器库中有两种API操作模式:一种是使用32bit的flow_id,一次向一个worker发送一个报文;另一种优化模式是一次性最多发送8个数据包给worker,使用15bit的flow_id。该模式由 rte_distributor_create() 函数中的类型字段指定。
16.1. 分发逻辑核操作¶
分发逻辑核执行了大部分的处理以确保数据包在worker之间公平分发。分发逻辑核的运作情况如下:
- 分发逻辑核的lcore线程通过调用
rte_distributor_process()来获取数据包。 - 所有的worker lcore与distributor lcore共享一条缓存线行,以便在worker和distributor之间传递消息和数据包。执行API调用将轮询所有worker的缓存行,以查看哪些worker正在请求数据包。
- 当有worker请求数据包时,distributor从第一步中传过来的一组数据包中取出数据包,并将其分发给worker。它检查每个数据包中存储在mbuf中RSS哈希字段中的“tag”,并记录每个worker正在处理的tag。
- 如果输入报文集中的下一个数据包有一个已经被worker处理的tag,则该数据包将排队等待worker的处理,并在下一个worker请求数据包时,优先考虑其他的数据包。这可以确保不会并发处理具有相同tag的两个报文,并且,具有相同tag的两个报文按输入顺序被处理。
- 一旦传递给执行API的所有报文已经分发给worker,或者已经排队等待给定tag的worker处理,则执行API返回给调用者。
Distributor lcore可以使用的其他功能有:
- rte_distributor_returned_pkts()
- rte_distributor_flush()
- rte_distributor_clear_returns()
其中最重要的API调用是 rte_distributor_returned_pkts() ,它只能在调用进程API的lcore上调用。它将所有worker core完成处理的所有数据包返回给调用者。在这组返回的数据包中,共享相同标签的所有数据包将按原始顺序返回。
NOTE: 如果worker lcore在内部缓存数据包进行批量传输,则共享tag的数据包可能会出现故障。一旦一个worker lcore请求一个新的数据包,distributor就会假定它已经完成了先前的数据包,因此具有相同tag的附加数据包可以安全地分配给其他worker,然后他们可能会更早地刷新缓冲的数据包,使数据包发生故障。
NOTE: 对于不共享公共数据包tag的数据包,不提供数据包排序保证。
使用上述执行过程及returned_pkts API,可以使用以下应用程序工作流,同时允许维护由tag识别的数据包流中的数据包顺序。
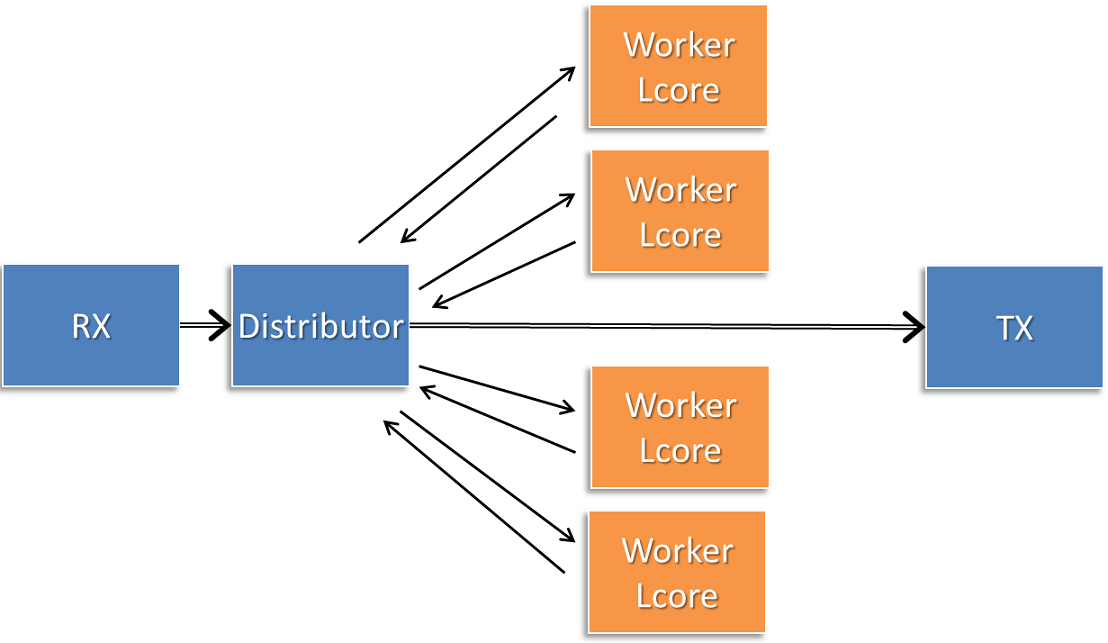
Fig. 16.2 Application workflow
之前提到的flush和clear_returns API调用可能不太用于进程和returned_pkts APIS,并且主要用于帮助对库进行单元测试。可以在DPDK API参考文档中找到这些功能及其用途的描述。
16.2. Worker Operation¶
Worker lcore是对distributor分发的数据包进行实际操作的lcore。 Worker调用rte_distributor_get_pkt() API在完成处理前一个数据包时请求一个新的数据包。前一个数据包应通过将其作为最终参数传递给该API调用而返回给分发器组件。
有时候可能需要改变worker lcore的数量,这取决于业务负载,即在较轻的负载时节省功率,可以worker通过调用rte_distributor_return_pkt()接口停止处理报文,以指示在完成当前数据包处理后,不需要新的数据包。